
|
Bhairav Mehta I am a PhD student at MIT, on leave until Fall 2021. I am an avid proponent of reform in machine learning, which allows me to spend time on teaching, mentoring, and alternative proposals for research distribution. I am lucky to be a GAAP mentor and a Machine Learning mentor, both of which are initiatives trying to level the playing field when it comes to machine learning academia.
Email: bhairavmehta95[AT]gmail.com Github: bhairavmehta95 |
|
|
| December 2020: Our ICLR 2021 workshop proposal, Beyond the Research Paper, has been accepted! |
| October 2020: The videos for our IROS 2020 workshop, Benchmarking Progress in Autonomous Driving, are now up! |
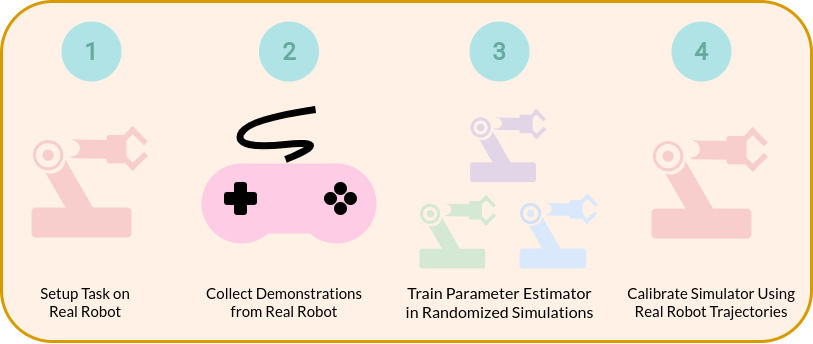
| October 2020: Our paper, A User's Guide to Calibrating Robotics Simulators, was accepted to CoRL2020! |
|
|
|
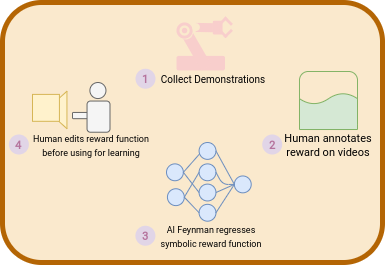
While recent years have been company to much progress in the reinforcement learning community, many tasks in use today still rely on carefully designed reward functions, many of which are products of constant tweaking and tuning by engineers and scientists. These reward functions, often dense, symbolic functions of state, don't exist in real world datasets, many of which are labeled by human experimenters - each with their own biases about desired behavior. In this work, we describe a new paradigm of extracting symbolic reward functions from noisy data called Interpretable Symbolic Reinforcement Learning (ISRL). ISRL allows for human experimenters to extract interpretable reward functions solely from data via symbolic regression. |
|
|
We explore current methods in the space of machine learning system identification, and push these algorithms to their limits along a variety of axes. We explore failure modes of each algorithm, and present a "user's guide" on when and where to use each. To present our results cleanly, we introduce the Simulation Parameter Estimation (SIPE) benchmark, which provides tools to efficiently test and compare past, current, and future algorithms in this space. |
|
|
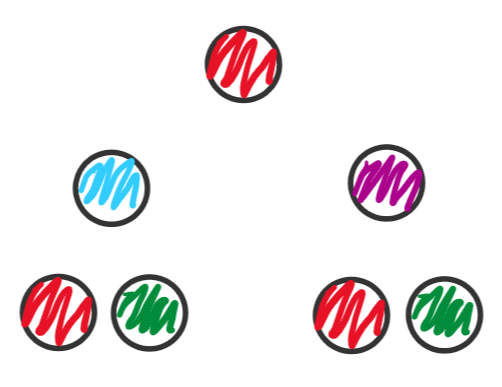
We show that bisimulation relations and metrics can be induced by graph neural networks, showing an equivalence between the original formulation of bisimulation on MDPs and the L2 distance induced by a particular type of GNN embedding. |
|
|
We explore the effects of pretraining on the |
|
|
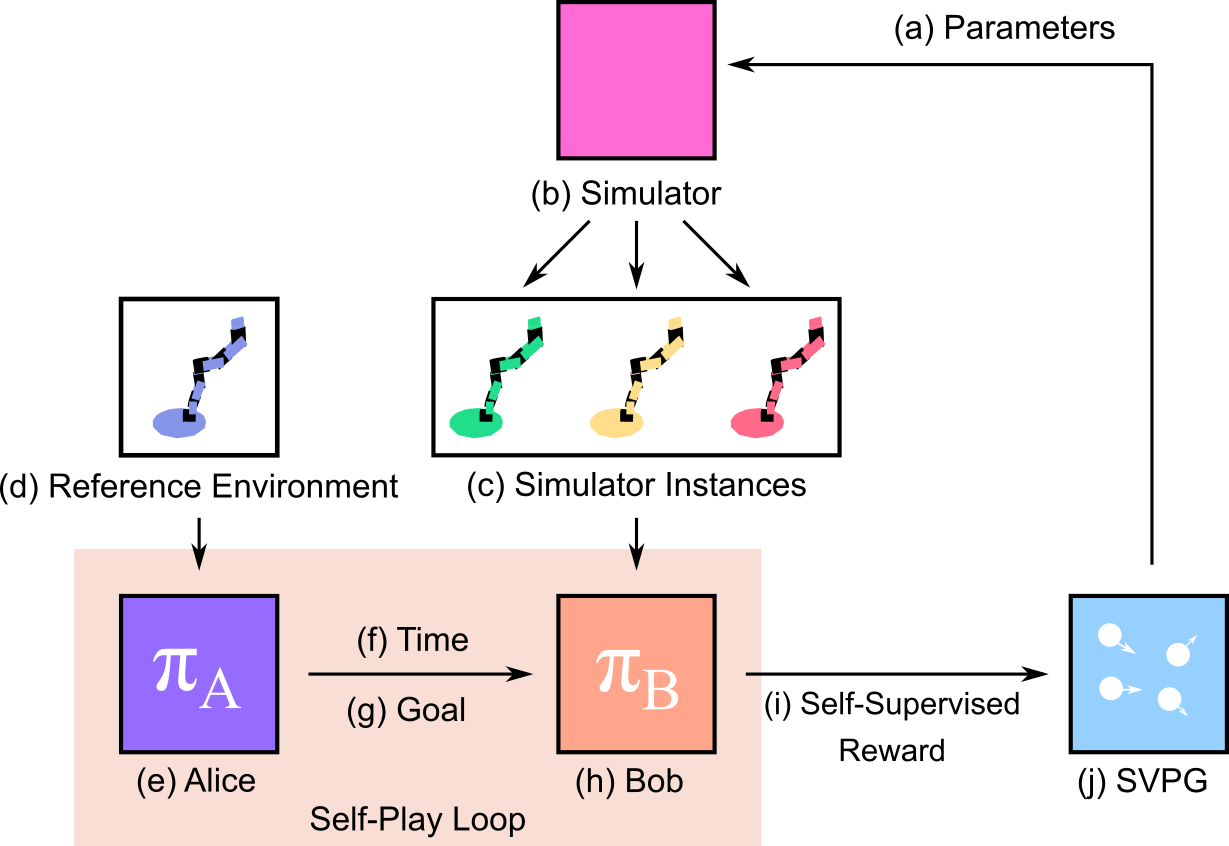
Can you learn domain randomization curricula with no rewards? We show that agents trained via self-play in the ADR framework outperform uniform domain randomization by magnitudes in both simulated and real-world transfer. |
|
|
In a follow-up to ADR, we show that |
|
|
Can Meta-RL use curriculum learning? In this work, we explore that question and find that curriculum learning stabilizes meta-RL in complex navigation and locomotion tasks. We also highlight issues with Meta-RL benchmarks by highlighting failure cases when we vary task distributions. |
|
|
We tackle the uniform sampling assumption in domain randomization and learn a randomization strategy, looking for the most informative environments. Our method shows significant improvements in agent performance, agent generalization, sample complexity, and interpretability over the traditional domain and dynamics randomization strategies. |
|
|
Outside of my research, I spend time working with Duckietown (Check out our simulator). I also help out with setting up infrastructure for our NIPS 2018 and ICRA 2019 AI Driving Olympics (AIDO) competitions, and even sometimes do video tutorials! |
|
|
We present a information retrieval approach to education and provide a end-to-end framework to go from raw text to a system where a student can learn about different topics such as History and Psychology, all while getting immediate feedback and recommendations on what to study from our system. |

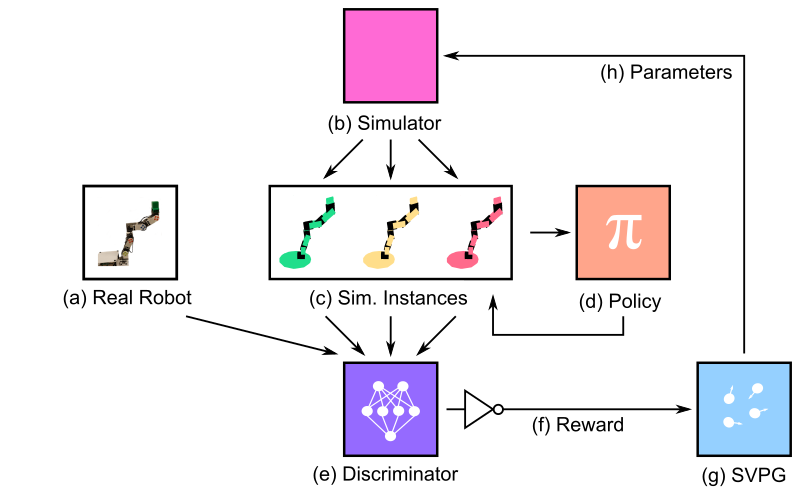
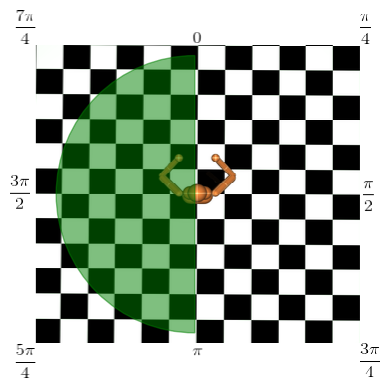
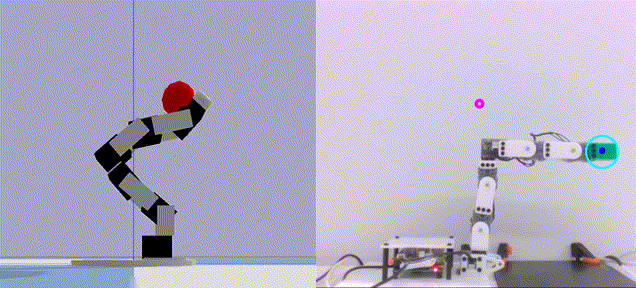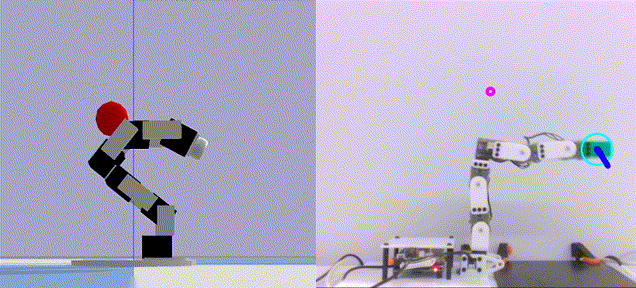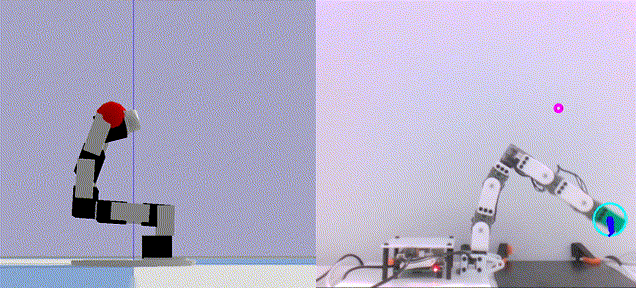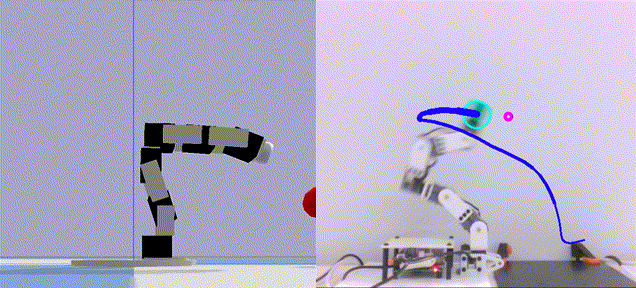
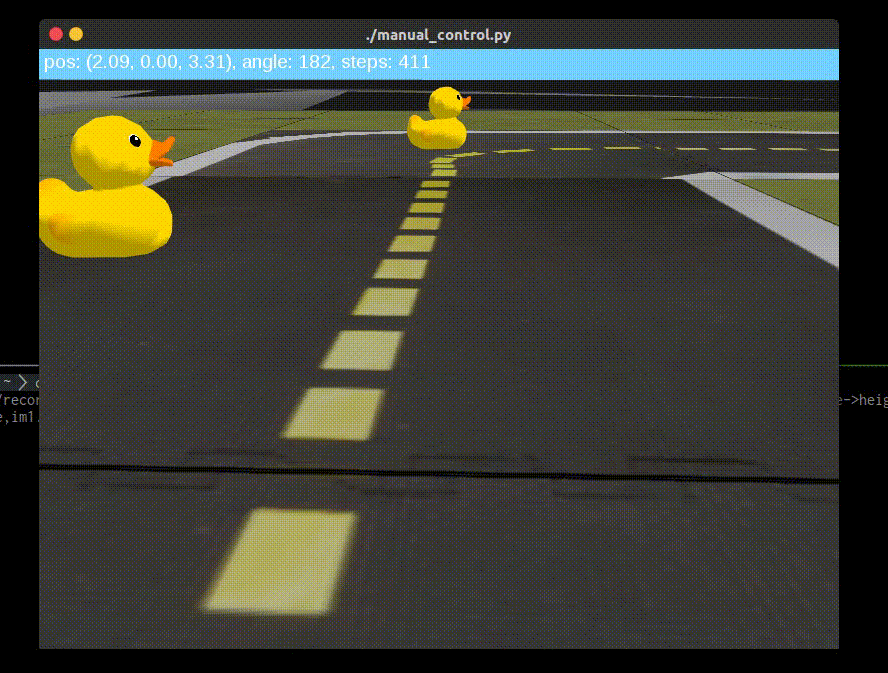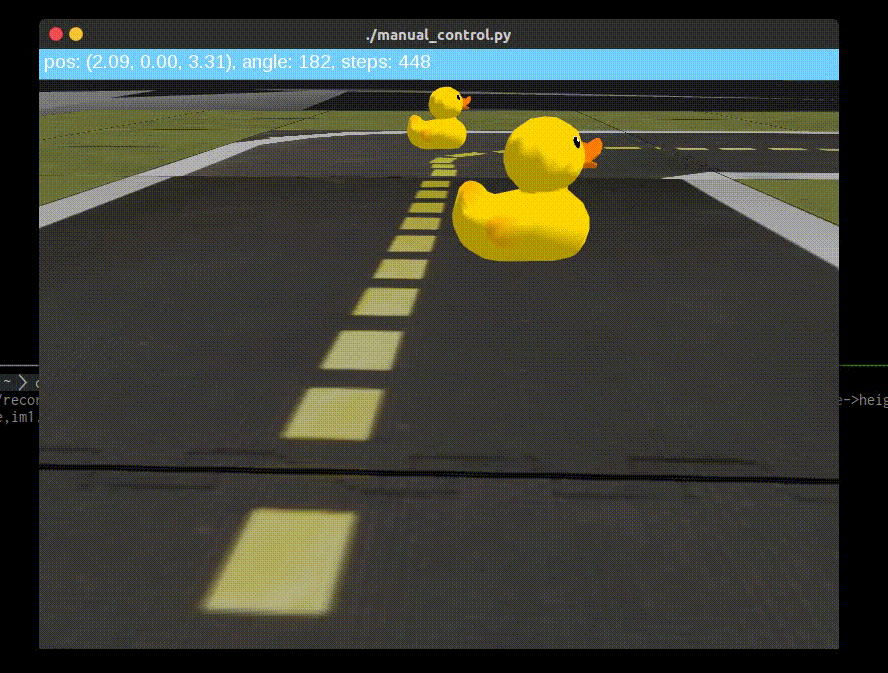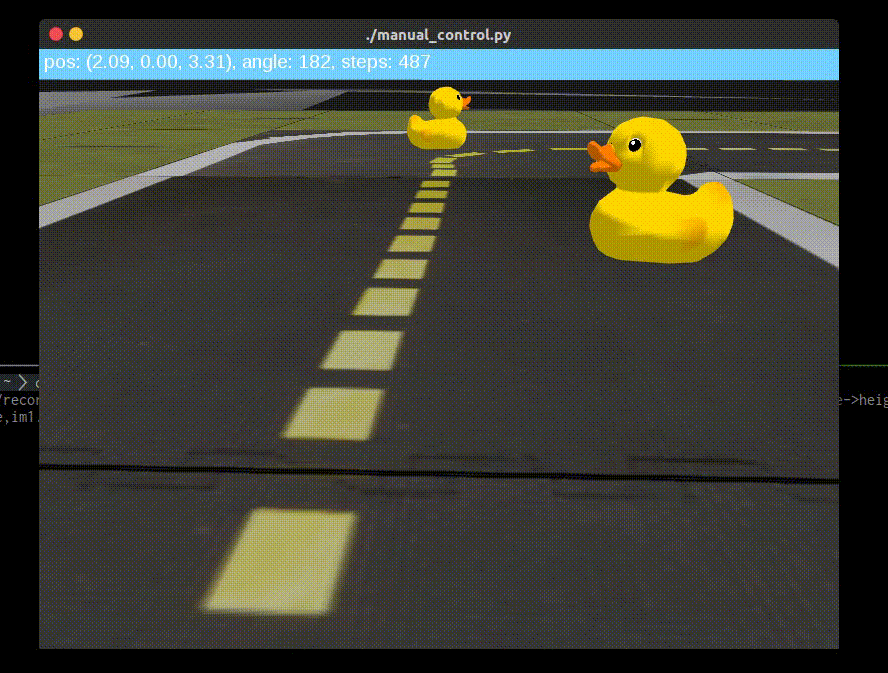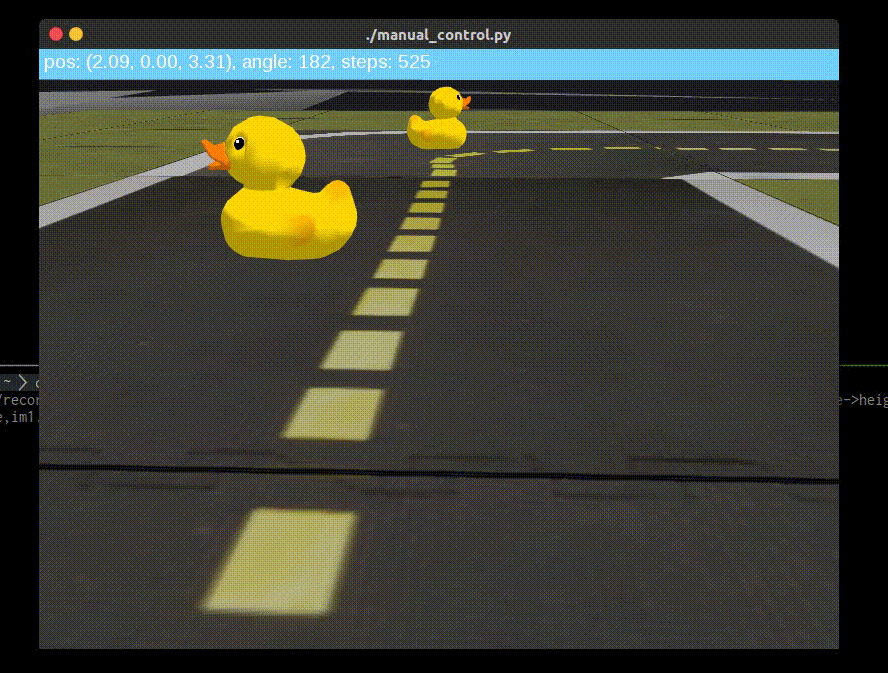

|
|
|
Aiming to train robots in simulation, I helped to develop agent environment code and DRL algorithms for a home support robot. |
|
|
Aiming to reproduce the results in "Parameter Space Noise for Exploration," my team and I entered into the ICLR 2018 Reproducability Challenge. Check out our final draft of the results here. |
|
|
I helped develop the main pipeline that transformed monocular camera images from the MAV's camera into a elevation height map. To then evaluate the usefulness and safety of landing sites, we used metrics like elevation, flatness and clutter to rank landing site candidates, and then used the quadcopter's motor controllers to autonomously land the vehicle. |
|
|
My main project team at Michigan, I developed software features such as localization, teleoperation, and odometry using C++ and ROS for an autonomous mining rover, which we utilized during the Robotic Mining Competition. |
|
|
There is no opportunity as big as education. It is an opportunity to make life-long learners; to excite students about the world; and to create explorers, scientists, entrepreneurs, entertainers, and engineers. But most students dread school. Many don't find relevance in their classes and many find their knowledge useless. Our mission at Project Chronicle is to empower those students with the ownership of stories and enhance their learning through the power of speech. Project Chronicle has students record their telling of a prompted topic. Our platform analyzes the student's response and give immediate feedback on both the accuracy and delivery of the content. The application both challenges the students to understand the material at a much deeper level than required by typical homework and leaves them with stories they can easily remember and share. It gives them confidence. It gives them comprehension. It gives them a voice. |



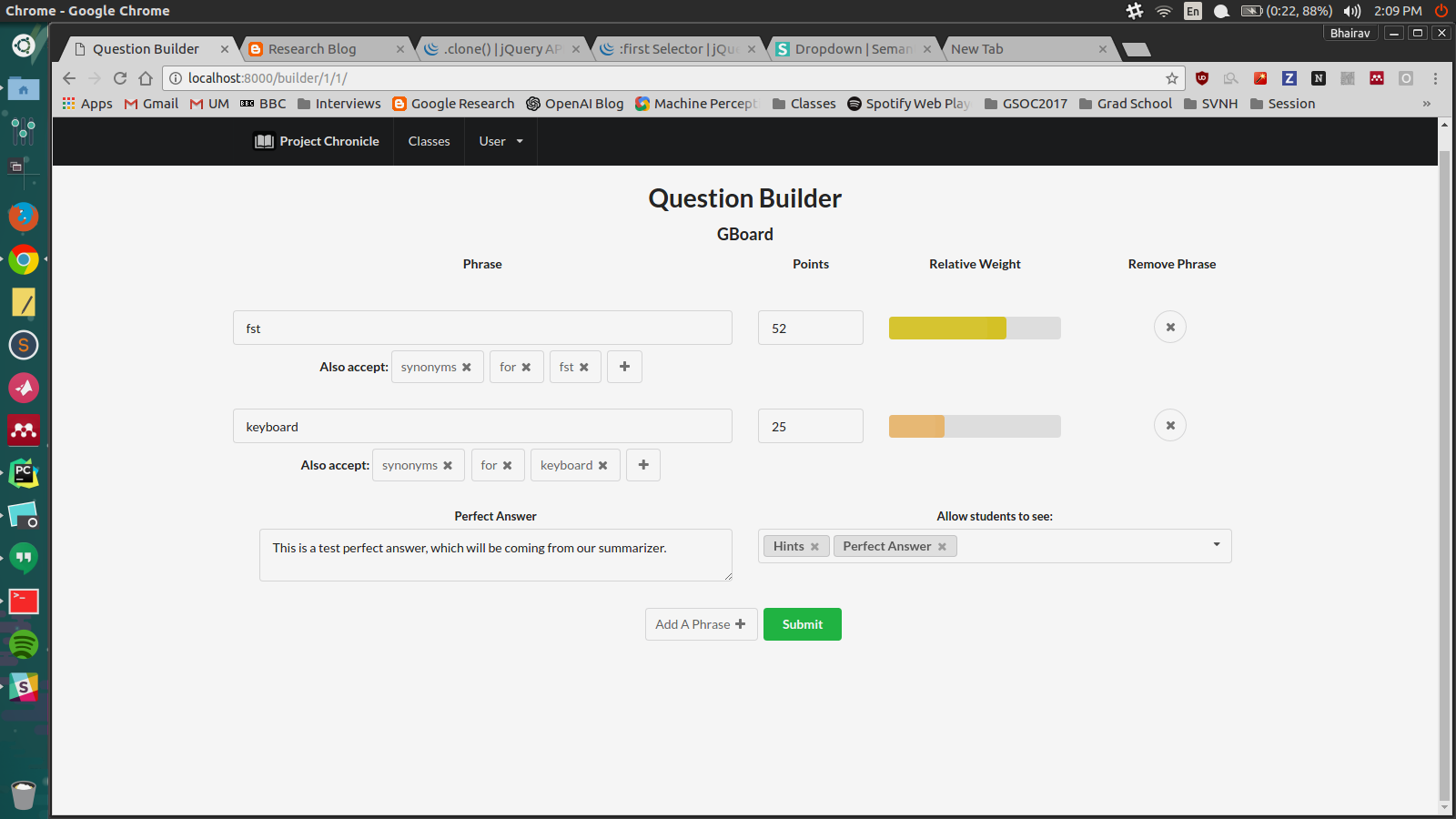
|
|
|
Some supplemental notes I have been writing for the class. |
|
|
I help teach Duckietown at UdeM, assisting with student projects and instructional exercises. |
|
|
As an inaugural Depth First Learning Fellow I created a curriculum to help understand the use of Stein's Method in Machine Learning, an increasingly popular method in the Machine / Deep / Reinforcement Learning communities. You can find the curriculum here. |



|
|
|
Nishant Nikhil - Summer 2019 Intern (Mila): Education and NLP |
|
|